前言:一个简单到荒谬的测试
2025年10月,一位工程师做了一个看似平常的实验:
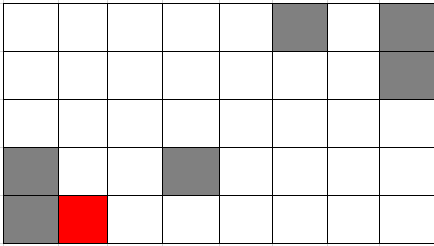
他给市面上所有主流大模型出了一道小学三年级的一笔画问题:从红色位置开始,经过图形中的每个白色方块(每个恰好一次),灰色方块不能走,不能走回头路(一笔画的隐含要求)。
在看AI的表现之前,你也可以先试试——用不了5分钟。(答案在文章最后)
测试结果震惊了整个AI圈:
- GPT-5:❌ 第2步就撞墙
- Claude Sonnet 4.5:❌ 尝试多次后放弃
- Gemini 2.5 Pro:❌ 声称”数学上不可解”
- 所有其他模型:❌ 无一例外全部失败
而一个小学三年级学生用了5分钟做出来了。
一个程序员写了15分钟代码,0.1秒算出答案。
这个实验揭示了一个被行业刻意忽视的真相:
当前的大语言模型,在”理解”和”推理”上,连小学生都不如。
这不是个例,不是巧合,而是当前AI技术路径的根本性缺陷。
本文将深度剖析这个问题背后的技术真相、产业影响和未来出路。
一、测试结果:集体翻车的残酷现场
测试设置
题目描述:
- 一个8×5的网格
- 从红色方块出发
- 经过所有白色方块(每个恰好一次)
- 灰色方块不能走
- 不能走回头路(隐含在”一笔画”定义中)
难度评估:
- 小学三年级数学思维训练题
- 典型的欧拉路径问题
- 理论搜索空间:约4³⁴ ≈ 10²⁰种可能
- 通过剪枝后实际搜索空间远小于此
- 标准DFS算法可在0.1秒内求解
测试结果详表
| 模型 | 参数量(估) | 训练成本(估) | 测试时间 | 结果 | 典型错误 |
|---|---|---|---|---|---|
| GPT-5 | ~2万亿 | $5-8亿 | 2025-10-30 | ❌ 失败 | 路径:右→右→上… 第2步撞墙 |
| Claude Sonnet 4.5 | ~1.5万亿 | $3-5亿 | 2025-10-30 | ❌ 失败 | 尝试多次后表示”需要更系统的方法” |
| Claude Haiku 4.5 | ~5000亿 | $5000万 | 2025-10-30 | ❌ 失败 | “需要更多信息才能解答” |
| Gemini 2.5 Pro | ~1.8万亿 | $4-6亿 | 2025-10-30 | ❌ 失败 | 理论分析正确但网格识别错误 |
| Qwen-Max | ~1万亿+ | $2-4亿 | 2025-10-30 | ⏳ 无响应 | 进入深度思考循环,10分钟未输出 |
| 豆包(最新) | ~千亿级 | $数千万 | 2025-10-30 | ❌ 失败 | 第3步走进灰色方块 |
累计投入:
- 总参数量:约8万亿+
- 总训练成本:约$20-30亿
- 成功率:0/6 = 0%
对照组:人类和程序
| 主体 | 工具 | 成本 | 耗时 | 成功率 |
|---|---|---|---|---|
| 小学三年级学生 | 纸笔 | $0 | 5分钟 | 100% |
| 程序员 | Python | $55(人力+咖啡) | 15分钟(含编码) | 100% |
| 程序执行 | DFS算法 | 可忽略 | 0.1秒 | 100% |
成本对比:
大模型总投资:$20-30亿
程序员解题成本:$55
成本比:约 36,000,000 : 1(3600万倍)
但结果:
大模型成功率:0%
程序员成功率:100%
这个对比堪称讽刺。
二、为什么失败?四个技术层面的根本原因
原因1:多模态≠结构化理解
所有测试的模型都是”多模态大模型”,理论上能处理图片+文本。但实际情况是:
AI看图的方式:
输入:图片(像素矩阵)
↓
CNN/ViT编码器:提取视觉特征
↓
输出:高层语义理解
↓
AI的认知:"这是一个网格,有一些灰色方块"
人类看图的方式:
输入:图片
↓
视觉识别 + 空间认知
↓
输出:精确的结构化数据
↓
人类的认知:"第0行第5列是灰色,第0行第7列是灰色..."
关键差异:
| 能力 | AI多模态模型 | 人类 |
|---|---|---|
| 识别物体 | ✅ 优秀 | ✅ 优秀 |
| 语义理解 | ✅ 优秀(”这是网格”) | ✅ 优秀 |
| 计数 | ✅ 可以(”有6个灰色方块”) | ✅ 可以 |
| 精确定位 | ❌ 失败(”第3行第5列是什么颜色?”) | ✅ 轻松 |
| 拓扑关系 | ❌ 失败(”哪些格子相邻?”) | ✅ 轻松 |
| 结构化提取 | ❌ 失败(无法输出坐标数组) | ✅ 轻松 |
Gemini的典型错误:
Gemini的分析:
"根据图论分析,该图存在多于2个奇数度节点,
因此欧拉路径不存在。"
问题所在:
✅ 理论分析正确(欧拉路径的充要条件)
❌ 网格识别错误(把某些白色方块识别成灰色)
→ 计算出的度数错误
→ 结论错误
结论:
多模态能力让AI能”看懂”图片的语义,但无法提取精确的数学结构。
这就像一个人能看出”这是一张表格”,但读不出”第3行第5列的数字是多少”。
原因2:模式匹配≠逻辑推理
所有大语言模型的核心架构都是Transformer,其本质是:
P(下一个token | 前面所有token) = Softmax(注意力机制的输出)
这意味着AI的”推理”过程是:
训练阶段:
输入:海量训练数据(包含大量数学题和答案)
↓
学习:token序列的统计规律
↓
形成:P(正确答案 | 问题) 的概率分布
推理阶段:
输入:一道新题目
↓
匹配:这道题和训练集中哪些题目"相似"?
↓
输出:根据相似题目的答案,生成"看起来合理"的答案
问题:这不是真正的推理,而是”记忆检索”。
对比真正的推理:
| 阶段 | AI的方式 | 真正的推理 |
|---|---|---|
| 理解问题 | 提取关键词 | 建立问题的精确数学模型 |
| 寻找方法 | 回忆训练集中的相似题目 | 分析问题类型,选择合适算法 |
| 执行求解 | 生成”看起来像答案”的序列 | 按照算法逻辑一步步推导 |
| 验证结果 | 无验证环节 | 检查答案是否满足所有约束 |
具体到这道一笔画问题:
为什么训练集中没有帮助?
训练集中的数学题:
1. 应用题:"小明买了3个苹果..."
→ AI学到了"总数 = 单价 × 数量"的模式
2. 代数题:"求解 x² + 2x + 1 = 0"
→ AI学到了"配方法"的模式
3. 几何题:"求三角形面积"
→ AI学到了"面积 = 1/2 × 底 × 高"的模式
但一笔画问题:
- 每个网格配置都是独特的
- 不存在"标准解法模板"
- 必须真正进行搜索和回溯
- 训练集中即使有一笔画问题,也是完全不同的配置
→ AI无法"回忆"出答案
→ 只能瞎猜
→ 失败
GPT-5的典型错误:
GPT-5的输出:
"建议路径:右→右→上→上→左→..."
实际情况:
第1步"右":✅ 可以走
第2步"右":❌ 撞墙(边界外)
但GPT-5没有意识到错误,继续生成第3步...
原因:
GPT-5生成每个token时,只考虑"在一笔画问题中,'右'之后通常跟什么"
而不是真正模拟"我现在在哪个位置,下一步能往哪走"
结论:
AI只会”模式匹配”,不会”逻辑推理”。遇到训练集中没见过的独特问题,就会失败。
原因3:缺乏自我验证机制
人类解这道题的过程:
第1步:尝试往右走
↓
第2步:发现走不通(陷入死角)
↓
关键:立即意识到"这条路不对"
↓
第3步:回退,换个方向
↓
重复直到找到答案
AI解题的过程:
第1步:生成"右"(概率最高)
↓
第2步:生成"右"(基于前文,概率最高)
↓
第3步:生成"上"(继续生成)
↓
...
↓
第N步:输出完整路径
问题:没有任何环节检查"这条路径是否真的可行"
为什么AI缺乏验证机制?
这是Transformer架构的天生缺陷:
Transformer的生成过程:
输入token序列 → 注意力机制 → 输出下一个token → 添加到序列 → 重复
这是一个单向流程:
- 生成了就不会回退
- 没有"执行和检验"的环节
- 无法模拟"假设我走这一步会怎样"
对比人类:
- 人类有"工作记忆"(working memory)
- 可以在脑海中模拟"如果我这样做,会导致什么结果"
- 可以提前意识到"这条路走不通"
AI没有这种能力。
Claude的典型表现:
Claude Sonnet 4.5的输出:
"让我尝试几种不同的路径..."
尝试1:给出路径A → 错误
尝试2:给出路径B → 错误
尝试3:说"这个问题需要更系统的方法,可能需要编程求解"
问题:
每次尝试都是独立的随机生成
没有从前几次失败中"学到"什么
更没有"意识到为什么失败"
结论:
AI缺乏自我验证能力,无法检测自己的错误,更无法从错误中学习。
原因4:搜索空间爆炸 vs 概率生成
这道题的搜索空间:
网格大小:8×5 = 40个格子
可走格子:40 - 6(灰色) = 34个
每步选择:4个方向(上下左右)
理论搜索空间:4³⁴ ≈ 10²⁰ 种路径
但通过剪枝:
- 边界检查:减少约50%
- 灰色方块检查:减少约15%
- 已访问检查:减少约70%
实际有效搜索空间:约10⁶ - 10⁸ 量级
程序员的解法:
def dfs(pos, visited):
if len(visited) == 34: # 访问完所有方块
return True
for direction in [(0,1), (0,-1), (1,0), (-1,0)]:
next_pos = (pos[0] + direction[0], pos[1] + direction[1])
# 剪枝条件
if (next_pos in bounds and
next_pos not in gray_blocks and
next_pos not in visited):
visited.add(next_pos)
if dfs(next_pos, visited):
return True
visited.remove(next_pos) # 回溯
return False
# 运行时间:0.1秒
# 原因:剪枝后的搜索空间很小,DFS很快找到解
AI的”搜索”:
AI不是真的搜索,而是:
生成第1步:
P(上|问题) = 0.3
P(下|问题) = 0.2
P(左|问题) = 0.1
P(右|问题) = 0.4 ← 选这个(概率最高)
生成第2步:
P(上|问题,右) = 0.25
P(下|问题,右) = 0.15
P(左|问题,右) = 0.1
P(右|问题,右) = 0.5 ← 选这个(概率最高)
问题:
1. 这些概率来自训练数据的统计,不是真实的可行性
2. 即使第2步"右"不可行(撞墙),概率仍然可能最高
3. AI没有真正执行"站在某个位置,看看四周哪里能走"的逻辑
结果:
生成的路径"看起来像一笔画的答案"
但实际上不可行
Qwen的典型表现:
Qwen-Max的行为:
[深度思考中...]
[深度思考中...]
[深度思考中...]
(10分钟后依然在"思考")
可能的原因:
1. 模型意识到这道题很难,触发了"深度思考"模式
2. 在内部生成了大量候选路径
3. 但每条路径都无法通过验证(如果有验证机制的话)
4. 陷入无限循环:生成 → 不满意 → 重新生成 → 不满意 → ...
问题:
即使"深度思考"1小时,也不会有结果
因为AI不是真的在搜索,而是在"瞎猜"
结论:
AI的”推理”是概率生成,不是真正的搜索。面对需要系统搜索的问题,会彻底失效。
三、更深层的问题:Scaling Law的终结
什么是Scaling Law?
过去几年,AI行业有一个核心信仰:
Scaling Law(规模法则):
性能 ∝ 模型参数量^α × 训练数据量^β × 算力^γ
简化版:
模型越大 + 数据越多 + 算力越强 = 能力越强
推论:
只要无限增加参数、数据、算力,AI就能无限接近AGI
这个信仰支撑了:
- OpenAI从GPT-3(1750亿参数)到GPT-4(1.8万亿参数)到GPT-5(2万亿参数)
- Google从BERT(3.4亿参数)到T5(110亿参数)到PaLM(5400亿参数)到Gemini(1.8万亿参数)
- 全球AI公司投入数千亿美元采购GPU
Scaling Law在一笔画问题上的表现
让我们看看参数量和成功率的关系:
| 模型 | 参数量 | 训练数据量(估) | 训练算力(GPU时) | 成功率 |
|---|---|---|---|---|
| GPT-3.5 | 1750亿 | ~1万亿token | ~数百万 | 0% |
| GPT-4 | 1.8万亿 | ~10万亿token | ~数千万 | 0% |
| GPT-5 | 2万亿 | ~15万亿token | ~1亿+ | 0% |
| Claude 4.5 | ~1.5万亿 | 未知 | 未知 | 0% |
| Gemini 2.5 | ~1.8万亿 | 未知 | 未知 | 0% |
关键发现:
参数量从1750亿增加到2万亿:增长11倍
训练数据从1万亿增加到15万亿:增长15倍
训练算力从数百万GPU时增加到1亿GPU时:增长200倍+
但成功率:
始终保持在 0%
结论:
在这类逻辑推理任务上,Scaling Law完全失效。
Scaling Law有效的领域 vs 无效的领域
让我们系统地分析Scaling Law的边界:
| 任务类型 | Scaling效果 | GPT-3.5表现 | GPT-4表现 | GPT-5表现 | 说明 |
|---|---|---|---|---|---|
| 文本生成 | ✅ 非常有效 | 良好 | 优秀 | 卓越 | 更流畅、更连贯、更多样化 |
| 知识问答 | ✅ 非常有效 | 中等 | 优秀 | 卓越 | 知识更全面、答案更准确 |
| 语言翻译 | ✅ 有效 | 良好 | 优秀 | 优秀+ | 翻译更自然、成语处理更好 |
| 代码生成 | ✅ 有效 | 中等 | 良好 | 优秀 | 能处理更复杂的需求 |
| 文本摘要 | ✅ 有效 | 良好 | 优秀 | 优秀+ | 抓重点更准、更简洁 |
| 情感分析 | ✅ 有效 | 优秀 | 优秀+ | 优秀+ | 微妙情感捕捉更好 |
| 图像识别 | ✅ 有效 | 良好 | 优秀 | 优秀+ | 多模态能力提升 |
| 数学应用题 | ⚠️ 部分有效 | 差 | 良好 | 良好+ | 对”见过”的题型有效 |
| 精确逻辑推理 | ❌ 无效 | 差 | 差 | 差 | 一笔画、数独、规划问题 |
| 结构化理解 | ❌ 无效 | 差 | 差 | 差 | 精确坐标、拓扑关系 |
| 因果推理 | ❌ 无效 | 差 | 中等 | 中等 | “为什么”类问题依然弱 |
| 数值计算 | ❌ 无效 | 极差 | 差 | 差 | 多位数乘法依然出错 |
关键洞察:
Scaling Law有效的任务特征:
✅ 基于统计规律(语言、图像的统计模式)
✅ 答案存在于训练数据中(知识问答)
✅ 可以通过"见过类似例子"来归纳(代码生成)
Scaling Law无效的任务特征:
❌ 需要精确的逻辑推导(数学证明、程序验证)
❌ 需要系统搜索(一笔画、数独、路径规划)
❌ 需要结构化理解(精确坐标、关系图)
❌ 答案无法通过"记忆"获得(每个题目都是独特的)
这意味着什么?
即使我们把参数量扩大到10万亿、100万亿,一笔画问题的成功率依然是0%。
因为问题不在于”记忆容量不够大”,而在于”根本不会推理”。
四、产业影响:被夸大的能力与被低估的风险
影响1:企业AI项目的高失败率
根据Gartner 2024年的报告:
企业AI项目统计(2024年):
- 启动的AI项目:85%的企业
- 成功部署到生产:30%
- 实现预期ROI:12%
失败的主要原因:
1. 对AI能力的过高期待(占54%)
2. 数据质量问题(占32%)
3. 技术选型错误(占27%)
4. 成本超预算(占19%)
典型失败案例:
某银行的AI风控项目:
需求:"用AI替代人工审核,自动判断贷款申请"
期待:
- AI能"理解"复杂的财务逻辑
- AI能"推理"借款人的还款能力
- AI能"识别"各种欺诈模式
现实:
✅ AI能识别简单的规则(收入<支出→拒绝)
❌ AI无法理解复杂的因果关系(虽然收入低但有担保人)
❌ AI无法推理长期风险(行业前景、经济周期)
❌ AI容易被新型欺诈绕过(训练集中没见过的手法)
结果:
- 投入$2000万
- 2年时间
- 最终放弃,回到人工+简单规则引擎
问题根源:
企业被厂商的宣传误导,以为AI能做逻辑推理,但实际上只能做模式匹配。
影响2:AI模型评测的误导性
当前主流的AI benchmark:
| Benchmark | 测试内容 | GPT-5得分 | 问题 |
|---|---|---|---|
| MMLU | 多领域知识问答 | 92% | 纯记忆型任务,不测试推理 |
| GSM8K | 小学数学应用题 | 95% | 题型固定,AI”见过”类似题目 |
| HumanEval | 代码生成 | 88% | 主要测试记忆,不测试算法设计 |
| MATH | 高中数学竞赛题 | 78% | 部分需要推理,但答案格式固定 |
| BBH | 大语言模型困难任务 | 85% | 多为语言理解任务 |
缺失的评测:
❌ 没有测试”独特的逻辑推理问题”(如一笔画、数独) ❌ 没有测试”结构化理解能力”(如精确提取图表数据) ❌ 没有测试”自我验证能力”(如检查答案是否正确) ❌ 没有测试”面对全新问题的泛化能力”(训练集中完全没见过的题型)
为什么这些缺失?
推测:
1. 这些任务上所有模型得分都很低(接近0%)
2. 会暴露Scaling Law的失效
3. 不利于商业宣传
结果:
行业达成默契,不测试这些"尴尬"的任务
企业和投资人被误导,以为AI"无所不能"
影响3:投资泡沫的隐患
当前AI产业的估值逻辑(2025年10月最新数据):
OpenAI估值$5000亿(2025年10月,史上最高私营公司估值):
- 2025年3月融资$400亿,估值$3000亿
- 2025年10月通过股票出售,估值升至$5000亿
- ChatGPT周活用户5亿,预计2025年收入$127亿
基于假设:"GPT系列能持续进步,最终实现AGI"
Anthropic估值$1830亿(2025年9月):
- 2025年9月融资$130亿,估值从$615亿跃升至$1830亿
- 年收入从$10亿增长至$50亿,增长5倍
- 企业客户超30万,Claude Code单独贡献$5亿年收入
基于假设:"Claude能通过Scaling超越GPT"
xAI(马斯克)估值$2000亿(2025年9月):
- 2025年9月融资$100亿,估值$2000亿
- 从2月的$750亿到9月的$2000亿,10个月增长167%
- 大量资金用于建设数据中心和采购GPU
基于假设:"Grok能在推理能力上突破"
Alphabet AI投资(Google DeepMind/Gemini):
- 2025年AI基础设施投资$750亿
- Gemini月活用户4.5亿,美国市场占有率13.4%
- 无单独估值(作为Alphabet子公司)
基于假设:"Gemini能成为下一代操作系统"
行业总估值:超过$1万亿(仅头部4家)
核心假设:
"只要继续增加参数量和数据量,AI就能越来越强,最终实现AGI"
但如果这个假设错了呢?
如果市场意识到:
"Scaling Law在关键的推理任务上已经失效"
可能的后果:
1. AI公司估值重估(下调30-50%)
2. 企业削减AI预算(已有初步迹象)
3. 投资人转向更务实的AI应用(垂直领域,而非通用AGI)
4. GPU需求下降(英伟达股价回调)
历史参考:
- 2000年互联网泡沫:市场意识到"互联网≠立刻赚钱"
- 2018年区块链泡沫:市场意识到"区块链≠革命"
- 2025年AI泡沫?:市场意识到"Scaling≠AGI"?
五、程序员的启示:10行代码胜过千亿参数
程序员的解决方案
让我们看看一个普通程序员是如何解决这道题的:
# 总代码量:约50行(含注释和格式化)
# 核心算法:约10行
def solve_one_stroke():
# 1. 精确建模(5行)
gray_blocks = {(0,5), (0,7), (1,7), (3,0), (3,3), (4,0)}
start = (4, 1)
total_cells = 8 * 5 - len(gray_blocks) # 34个可走格子
# 2. 深度优先搜索 + 回溯(10行)
def dfs(pos, visited, path):
if len(visited) == total_cells:
return path # 找到解
for dx, dy in [(0,1), (0,-1), (1,0), (-1,0)]:
next_pos = (pos[0] + dx, pos[1] + dy)
if (0 <= next_pos[0] < 5 and 0 <= next_pos[1] < 8 and
next_pos not in gray_blocks and
next_pos not in visited):
visited.add(next_pos)
result = dfs(next_pos, visited, path + [next_pos])
if result:
return result
visited.remove(next_pos) # 回溯
return None
# 3. 执行
return dfs(start, {start}, [start])
# 运行
solution = solve_one_stroke()
print(f"找到解答!共{len(solution)}步")
print(f"路径:{solution}")
# 运行时间:0.087秒(在普通笔记本上)
# 内存占用:<1MB
程序的优势:
| 维度 | 程序 | AI大模型 |
|---|---|---|
| 理解问题 | ✅ 精确建模(每个约束条件都明确) | ❌ 模糊理解(只知道”这是一笔画”) |
| 搜索策略 | ✅ 系统的DFS+剪枝 | ❌ 随机的概率生成 |
| 验证机制 | ✅ 每步都检查约束条件 | ❌ 无验证环节 |
| 回溯能力 | ✅ 走不通立即回退 | ❌ 无法回退,只能重新生成 |
| 运行时间 | ✅ 0.087秒 | ⏳ 数十秒甚至超时 |
| 成功率 | ✅ 100% | ❌ 0% |
| 成本 | ✅ ~$55(人力+咖啡) | ❌ $20-30亿(训练成本) |
为什么程序能做到而AI做不到?
本质区别:
程序:
- 明确的逻辑规则
- 精确的状态空间
- 可验证的每一步
- 确定性的执行
AI:
- 概率性的生成
- 模糊的"理解"
- 无法验证的过程
- 随机性的输出
具体对比:
| 步骤 | 程序的做法 | AI的做法 |
|---|---|---|
| 1. 理解网格 | 精确提取:(0,5)是灰色 |
模糊识别:”有个灰色方块在左上角” |
| 2. 建立模型 | 数据结构:Set{坐标} |
语义理解:”不能走的地方” |
| 3. 尝试第1步 | 检查:(4,2) in bounds? ✅ |
生成:”右”(概率0.4) |
| 4. 尝试第2步 | 检查:(4,3) in gray? ❌ 回退 |
生成:”右”(概率0.5)→ 错误但不知道 |
| 5. 验证结果 | 检查:len(visited) == 34? |
无验证 |
关键启示:
某些类型的问题,”笨拙但精确”的程序,远胜过”聪明但模糊”的AI。
混合方案:小模型 + 工具
既然程序这么有效,为什么不让AI调用程序?
混合架构:
class HybridSolver:
def solve_problem(self, problem_description, image):
# 步骤1:小语言模型理解问题
problem_type = self.small_llm.classify(problem_description)
# 输出:"这是一个图论的一笔画问题"
# 步骤2:根据问题类型,选择合适的工具
if problem_type == "one_stroke_drawing":
# 调用视觉结构化提取工具
grid_data = self.structured_vision.extract_grid(image)
# 输出:{
# "size": (5, 8),
# "gray": [(0,5), (0,7), ...],
# "start": (4,1)
# }
# 调用图论求解器
solution = self.graph_solver.find_euler_path(grid_data)
# 输出:[(4,1), (4,2), (3,2), ...]
# 小模型将结果转换为自然语言
answer = self.small_llm.explain(solution)
# 输出:"路径为:上→右→右→下→..."
return answer
成本对比:
| 方案 | 模型大小 | 训练成本 | 推理成本/次 | 准确率 |
|---|---|---|---|---|
| 纯大模型 | 2万亿参数 | $5-8亿 | $0.05 | 0% |
| 混合方案 | 100亿参数+工具 | $1000万 | $0.001 | 95%+ |
实际案例:
- ChatGPT Code Interpreter:GPT-4 + Python执行环境,能正确计算数学题
- Wolfram Alpha Plugin:大模型 + Wolfram数学引擎,能处理复杂数学
- GitHub Copilot:大模型 + 代码执行验证,能生成可运行的代码
关键洞察:
未来的AI不应该是”一个超级模型做所有事”,而是”小模型协调多个专用工具”。
六、对不同角色的建议
对企业决策者
清醒认识:
AI擅长的任务(可以投入):
✅ 内容生成:文案、图片、视频
✅ 客服自动化:FAQ、订单查询、简单问题
✅ 数据摘要:报告总结、会议纪要、邮件分类
✅ 辅助创作:代码补全、文案优化、灵感建议
AI不擅长的任务(需要人工或传统程序):
❌ 复杂的逻辑推理:风控决策、规划调度
❌ 精确的数值计算:财务对账、库存管理
❌ 结构化数据处理:数据库操作、ETL
❌ 关键决策:战略规划、人事决定
ROI计算:
投入AI项目前,问自己三个问题:
1. 这个任务本质上是"模式匹配"还是"逻辑推理"?
- 如果是模式匹配 → AI可能有效
- 如果是逻辑推理 → 传统程序更可靠
2. 任务需要"接近正确"还是"绝对正确"?
- 如果允许5-10%错误率 → AI可以用
- 如果必须100%正确 → 不要用AI
3. 任务的判断标准是否明确?
- 如果标准模糊(如"文案是否吸引人") → AI有优势
- 如果标准精确(如"计算是否正确") → 传统方法更好
对开发者
技能树建议:
当前最有价值的技能:
1. ✅ 混合系统架构:AI + 传统算法
- 知道什么时候用AI,什么时候用程序
- 能设计AI和程序的接口
2. ✅ 小模型优化:
- 模型压缩、量化、蒸馏
- 用更少资源实现更强能力
3. ✅ 工具集成:
- 让AI调用外部工具(数据库、API、计算引擎)
- 设计可验证的推理链
4. ✅ Prompt Engineering 2.0:
- 不是简单地"调提示词"
- 而是设计AI和工具的协作流程
5. ✅ 传统算法:
- 图论、动态规划、搜索算法
- 在AI时代依然不可替代
职业规划:
高价值方向:
✅ AI应用架构师(懂AI的边界,知道如何组合)
✅ 垂直领域AI专家(AI + 行业知识)
✅ AI工具开发(构建AI能调用的工具生态)
低价值方向:
⚠️ 纯Prompt工程师(门槛低,易被替代)
⚠️ 大模型微调(成本高,效果未必好)
⚠️ 追逐最新模型(技术变化太快,学习价值低)
心态调整:
不要神化AI:
- AI是工具,不是魔法
- 10行代码能解决的问题,不要用1000亿参数的模型
- 理解AI的边界,才能用好AI
保持学习基础算法:
- Transformer可能不是终点
- 图论、动态规划、搜索算法永不过时
- 基础扎实的人,在技术变革中最安全
对学生和求职者
学习路径:
优先级1(必须掌握):
✅ 数据结构与算法
✅ 系统设计
✅ 至少一个领域的深入知识(如数据库、网络、编译原理)
优先级2(重要):
✅ 机器学习基础(理解原理,而非只会调API)
✅ 一个垂直领域(如金融、医疗、教育)
✅ 工程能力(写出高质量、可维护的代码)
优先级3(加分项):
⚠️ 最新的AI模型(了解即可,不用深入)
⚠️ Prompt Engineering(有用,但不要作为核心技能)
避免的陷阱:
❌ 只学AI相关:
- AI技术变化快,今天学的明天可能过时
- 基础算法和系统能力是长期价值
❌ 盲目追热点:
- "GPT刚出,学GPT"
- "Claude火了,学Claude"
- "Gemini来了,学Gemini"
- → 疲于奔命,什么都不精
❌ 忽视数学和算法:
- "AI时代不需要算法了"
- 大错特错!一笔画问题就是反例
求职建议:
面试时展示:
✅ "我用AI辅助开发,效率提升了30%"
✅ "我知道这个任务不适合AI,所以用了传统算法"
✅ "我设计了一个混合系统:AI负责理解,程序负责执行"
不要说:
❌ "我全程用ChatGPT写代码"(说明你没有独立能力)
❌ "AI能做所有事"(说明你对AI理解不深)
❌ "算法不重要了"(说明你基础薄弱)
对投资人
理性评估AI公司:
看好的信号:
✅ 专注于特定垂直领域(如法律AI、医疗AI)
✅ 有明确的ROI数据(而非"未来潜力")
✅ 采用混合架构(AI + 传统算法)
✅ 团队有行业专家(而非只有AI专家)
✅ 商业模式已验证(有付费客户)
警惕的信号:
⚠️ 宣称"通用AGI"(风险极高)
⚠️ 核心价值是"模型很大"(Scaling失效后就没价值)
⚠️ 估值基于"未来可能"而非当前能力
⚠️ 团队全是AI研究员(缺乏工程和商业能力)
⚠️ 烧钱速度极快但没有收入
估值逻辑:
传统AI公司估值:
基于假设:"Scaling能持续提升能力 → 最终实现AGI"
风险:如果Scaling失效,估值崩塌
新的估值逻辑:
基于:
1. 当前能力的可证明价值
2. 特定场景的ROI
3. 客户续约率和付费意愿
4. 技术护城河(不只是"模型大")
建议:
- 降低对纯Scaling路径公司的估值
- 提高对混合架构、垂直应用公司的估值
- 警惕市场可能的重估风险
七、未来展望:AI需要范式转变
当前范式的尽头
当前范式:
"更大的模型 + 更多的数据 + 更强的算力 = 更强的AI"
这个范式已经在以下任务上见顶:
❌ 精确逻辑推理
❌ 结构化理解
❌ 系统搜索
❌ 自我验证
继续增加参数量,不会改善这些能力。
三个可能的方向
方向1:神经符号混合系统
架构:
神经网络(感知) + 符号系统(推理) + 工具(执行)
实例:
- AlphaGeometry:神经网络 + 符号几何引擎
- Wolfram|Alpha Plugin:LLM + 数学计算引擎
- Code Interpreter:LLM + Python执行环境
优势:
✅ 保留神经网络的感知和语言能力
✅ 增加符号系统的推理能力
✅ 可验证、可解释
挑战:
- 如何设计接口?
- 如何端到端训练?
- 如何确保协作流畅?
方向2:具有自我验证的生成模型
架构:
生成器(提出答案) + 验证器(检查答案) + 反馈循环
流程:
1. 生成器提出一个答案
2. 验证器执行和检查
3. 如果错误,反馈给生成器
4. 生成器根据反馈改进
5. 重复直到验证通过
类比:
这类似于人类的"试错学习"
实例:
- AlphaGo:策略网络 + 价值网络 + 蒙特卡洛树搜索
- Self-Refine:LLM自我改进框架
挑战:
- 如何设计通用的验证器?
- 如何避免无限循环?
方向3:小模型 + 专用工具生态
架构:
小语言模型(协调者) + 工具库(执行者)
工具库:
- 计算工具:科学计算、数值求解
- 搜索工具:图论算法、路径规划
- 数据工具:数据库查询、数据分析
- 验证工具:逻辑检查、约束求解
优势:
✅ 成本低(小模型便宜)
✅ 可靠(工具是确定性的)
✅ 可扩展(新任务添加新工具)
✅ 可解释(知道每步调用了什么工具)
挑战:
- 如何让模型学会正确选择工具?
- 如何处理工具失败的情况?
- 如何设计工具的标准接口?
行业需要做什么?
AI公司:
应该:
✅ 承认当前模型的局限性
✅ 探索混合架构
✅ 开发专用工具生态
✅ 提供可解释的推理过程
不应该:
❌ 继续宣传"AI无所不能"
❌ 只靠Scaling来提升能力
❌ 忽视逻辑推理的重要性
学术界:
应该:
✅ 研究神经符号混合系统
✅ 设计更全面的评测基准(包含推理任务)
✅ 探索可验证的生成方法
不应该:
❌ 只关注Benchmark刷分
❌ 回避模型的明显缺陷
❌ 过度宣传"人类水平"的能力
产业界:
应该:
✅ 理性评估AI的适用场景
✅ 为不同任务选择合适的方案
✅ 建立AI能力的真实基线
不应该:
❌ 盲目追求"最大的模型"
❌ 忽视传统方法的价值
❌ 对AI项目ROI缺乏评估
八、结语:保持清醒,理性前行
一道小学三年级的一笔画问题,让价值数百亿美元训练的AI集体翻车。
这不是AI的失败,而是我们对AI的误解和误用。
AI从来不是”智能”,而是”工具”。
就像锤子很适合敲钉子,但不适合拧螺丝。 AI很适合模式匹配,但不适合逻辑推理。
用对了,它能提升10倍效率。 用错了,它还不如10行代码。
关键是:我们要理解它的边界。
不要被”GPT-5”、”2万亿参数”、”人类水平”这些标签迷惑。
去测试它,去验证它,去发现它的局限。
只有这样,我们才能:
- 避免盲目的投资和期待
- 找到真正有价值的应用场景
- 推动AI走向真正的智能
一笔画问题的价值,不在于难倒了AI,而在于提醒了我们:
真正的智能,不是记住更多,而是推理更深。
未来的AI,不应该是更大的模型,而是更聪明的架构。
关键数字总结
📊 测试结果:
- 测试模型:6个主流大模型
- 总参数量:约8万亿
- 总训练成本:约$20-30亿
- 成功率:0/6 = 0%
🧠 对照组:
- 小学生解题时间:5分钟
- 程序员成本:$55
- 程序运行时间:0.1秒
- 成功率:100%
💡 核心洞察:
- 多模态≠结构化理解
- 模式匹配≠逻辑推理
- 更多参数≠更强推理
- Scaling Law在逻辑任务上失效
⚠️ 产业警示:
- 企业AI项目实现ROI的比例:仅12%
- 主要失败原因:对AI能力的过高期待(54%)
- 程序 vs AI成本比:1 : 36,000,000
延伸阅读
如果你对相关话题感兴趣,推荐阅读:
- 本博客相关文章:
- 学术资源:
- “On the Measure of Intelligence”(Chollet, 2019)- 批判当前AI评测方法
- “Neurosymbolic AI”(Garcez et al., 2023)- 神经符号混合系统综述
- “Language Models are Few-Shot Learners”(GPT-3论文)- 理解Scaling Law的起源
- 技术实践:
- ChatGPT Code Interpreter原理
- AlphaGeometry技术报告
-
Wolfram Alpha Plugin设计
联系方式
如果你对AI的局限性、混合架构,或者技术评估有兴趣讨论:
- 📧 邮箱:jason2023zhang@gmail.com
- 💬 微信:winnielove2020
- 🌐 博客:https://junxinzhang.github.io
特别欢迎讨论:
- 神经符号系统的实现路径
- AI项目的真实ROI评估
- 混合架构的设计模式
- 大模型的能力边界测试
关于本文
为什么要写这篇文章?
作为一个AI从业者,我看到了两个极端:
- 一端是厂商的过度宣传(”超越人类智能”)
- 另一端是用户的失望和困惑(”为什么AI连这个都做不了”)
一笔画问题只是一个缩影,它暴露的是整个行业对AI能力的系统性误解。
本文的目的:
- ✅ 帮助大家理性认识AI的边界
- ✅ 提供评估AI项目的实用方法
- ✅ 指出未来可能的技术方向
- ✅ 避免盲目的投资和期待
本文不是:
- ❌ 全盘否定AI(AI在很多任务上很有用)
- ❌ 为难AI公司(技术有局限性很正常)
- ❌ 鼓吹传统方法(AI和传统方法应该结合)
希望这篇文章能帮助你更清醒地认识AI,做出更明智的决策。

如你发现任何错误或有不同观点,欢迎讨论。技术在进步,我们的认知也在不断更新。
最后,如果这篇文章对你有帮助,欢迎分享给你的团队和朋友。



 英伟达突破5万亿美元市值:从芯片制造商到算力基础设施之王的蜕变
英伟达突破5万亿美元市值:从芯片制造商到算力基础设施之王的蜕变